
Beyond the Hype: Why We Chose Redis Streams Over Kafka for Microservices Communication
I’m writing this article based on my personal experience implementing a production-ready solution using Redis Streams with my team. This is a result of a few months working with Redis Streams, development and maintenance. If you’re not sure, which solution to choose, I hope this article helps you choose the best solution for your needs.
Introduction
The problem we were facing was quite common. The question was how to communicate between two microservices in a simple, fast, and reliable way. Our first thought was to choose between two of the most popular solutions: RabbitMQ or Kafka. We wanted something that could handle higher throughput in the future, so it seemed, that Kafka would be better choice. It met all of the above requirements, and it’s also a resume-friendly solution.
However, there were two problems: we didn’t have it in our stack yet, and nobody on the team had experience with Kafka or operating a Kafka server. Also, since the project runs on PHP, integration is not as straightforward as it is with Java for example. Additionally, a PHP extension to integrate with Kafka was not well supported these days, and we didn’t feel comfortable using it. Nowadays, of course, the situation is different, and there are some stable solutions for PHP Kafka.
When we were focused on learning Kafka, and all the features that we don’t actually need, someone suggested that Redis has a messaging system called Redis Streams. So we began researching it.
How Redis can be an alternative to Kafka?
When I first heard about Streams, I thought, “Okay, I’m not sure if it will help, but let’s see.” I started researching, and step by step, I became more and more convinced that it actually meets all of our expectations, and it’s much easier from operational perspective. Also we already had it in our stack.
So, we had to compare Kafka and Redis. The best option is probably to write down some architectural drivers and compare them. Let’s take a few:
- Persistence and replayability: We don’t need too much of this.
- Operational complexity: It’s an MVP, so it needs to be as simple as possible.
- Performance: We might need to handle high throughput in the future.
- Learning curve: Smaller is better.
| Driver | Kafka | Redis Streams |
|---|---|---|
| persistence and replayability | persisting in cheaper disk space, and can replay from the very beginning | persisting data in more expensive RAM, long streams are possible but more expensive |
| operational complexity | High | Low or Very Low if you have Redis already in stack |
| performance | Highest throughput Medium latency | High throughput Low latency |
| learning curve | Steep, needs to understand how the system works and how to integrate it | Gentle, the same well known API as used in many different cases. Easy to integrate, every language have it applied |
Kafka often achieves higher throughput at the expense of higher latency, while Redis Streams has lower latency but its maximum throughput may be lower.
Following those few most important drivers, it seems that Redis Streams could be a good solution. What still leaves me unconvinced is the lack of information about the real problems we could face. Most articles are theoretical. That’s also why I decided to write this post.
Thankfully, I finally found a document that totally convinced me. It was official document, prepared by Redis, and it dives deeper into the details of the comparison between Kafka and Redis Streams. There are many examples with visual presentations. You can download the document from the Redis website: https://redis.io/resources/understanding-streams-in-redis-and-kafka-a-visual-guide/. This document also shows some great ideas, how to achieve similar features as in Kafka, like partitioning.
How Redis Streams works?
The above document explains everything very well, but I will describe the basics here. I encourage you to test these commands using Redis Insight (https://redis.io/insight/). This will demonstrate how simple it is to start using streams.
Simple messaging
The easiest way to start working with streams is to set up a stream and start consuming messages. In fact, the only way to create a stream is to simply start sending messages to it. If you try:
XADD mymessages * payload "This is the payload of a message"
This will automatically create the stream named mymessages and add a message with a payload field containing the message in quotes.
Okay, so now we should read this message somehow. We can do that by running:
XREAD COUNT 1 STREAMS mymessages 0-0
Output:
1) 1) "mymessages"
2) 1) 1) 1526984818136-0
2) 1) "payload"
2) This is the payload of a message"
Where 1 you can specify how many messages you want to read from the stream at once. You can increase this number if you’re processing more messages at once. After reading and processing it properly, you can remove the message by running the following command:
XDEL mymessages 1526984818136-0
This will clean up already processed messages from our stream.
That’s how it works for the simplest case, with one consumer.
Consumer groups
Okay, we know how to use streams for one consumer. But the real world is not that simple. You may want to read streams from multiple instances of a single microservice or even multiple microservices. How can we manage this case while ensuring deliverability and preventing one message from being processed multiple times? This is where consumer groups shine.
To create a consumer group, simply run:
XGROUP CREATE mymessages mygroup 0
You can use any name to describe the group of services that will consume those messages. Next, when you want to assign a specific instance of a microservice, for example, what do you do? As always, there is an upsert approach, so you just need to start listening from a specific group.
XREADGROUP GROUP mygroup consumerid STREAMS mymessages 0
What is consumerid? It can be any string that helps you identify the specific consumer in case of any problems with consumption. For example, if you’re using Kubernetes, you can use the container ID. This will help you identify the correct container in your infrastructure.
Since Redis promises to guarantee message delivery within a group, we need to inform it when a message has been properly processed. Otherwise, Redis won’t know if it can take another entry from the stream, and it won’t be able to properly share entries between all consumers. That’s why we need to acknowledge it.
XACK mymessages mygroup 1526984818136-0
Now the message is marked as acknowledged and will not be delivered again to the same consumer group.
Control stream length
As with multiple consumer groups you need to keep longer streams. You can’t just remove message after processing, because they have to be delivered to all groups. Since messages are stored in memory, you should monitor, and control its size to avoid overflow. You can control the size manually by running:
XTRIM mymessages MAXLEN 1000
This will reduce the length of the stream to 1,000 by removing the oldest messages. However, this method may be inefficient.
There is a better solution. You can configure Redis to automatically adjust the stream length, by modifying XADD command following way:
XADD mymessages MAXLEN ~ 1000 * payload "This is the payload of a message"
You’ve probably noticed the ~ after MAXLEN; it stands for “approximate trimming.” This makes Redis less strict about the stream’s length, allowing it to trim messages asynchronously in the background. This approach is far more efficient as it doesn’t block write operations. In my case, with the stream length oscillating around just a few messages, so this shouldn’t be a problem in most cases.
Real world problems
Of course, the real world is not as beautiful as documentation will describe to you. There are always known problems that you’ll only face when you start using Redis. It’s also good to mention that every specific use case can cause different problems and expose different limitations. I’ve encountered some of these problems and will describe them here, along with possible solutions that you can use when you encounter them.
What if Redis is out?
The first thing you should consider if you want to use this solution in production is ensuring high availability. There are two main ways to do so: Redis Sentinel or Redis Cluster. I won’t show you how to configure either of them in your infrastructure because that would require an entire article, and this one is already quite long. However, there is an alternative if you’re building an MVP and have less time for configuration.
If your project is written in Node.js, there is one more option. There’s a library called ioredis that has a very useful feature. It’s an offline queue. What does this mean? When you have a single instance of Redis without any high availability configuration and Redis goes down, either on purpose or accidentally, ioredis will keep all the redis commands you’ve sent, in memory. Once Redis is back, all the queued commands will be sent to Redis, and all your subsequent commands will be sent normally. In this case, you won’t lose any messages, even if Redis stops working.
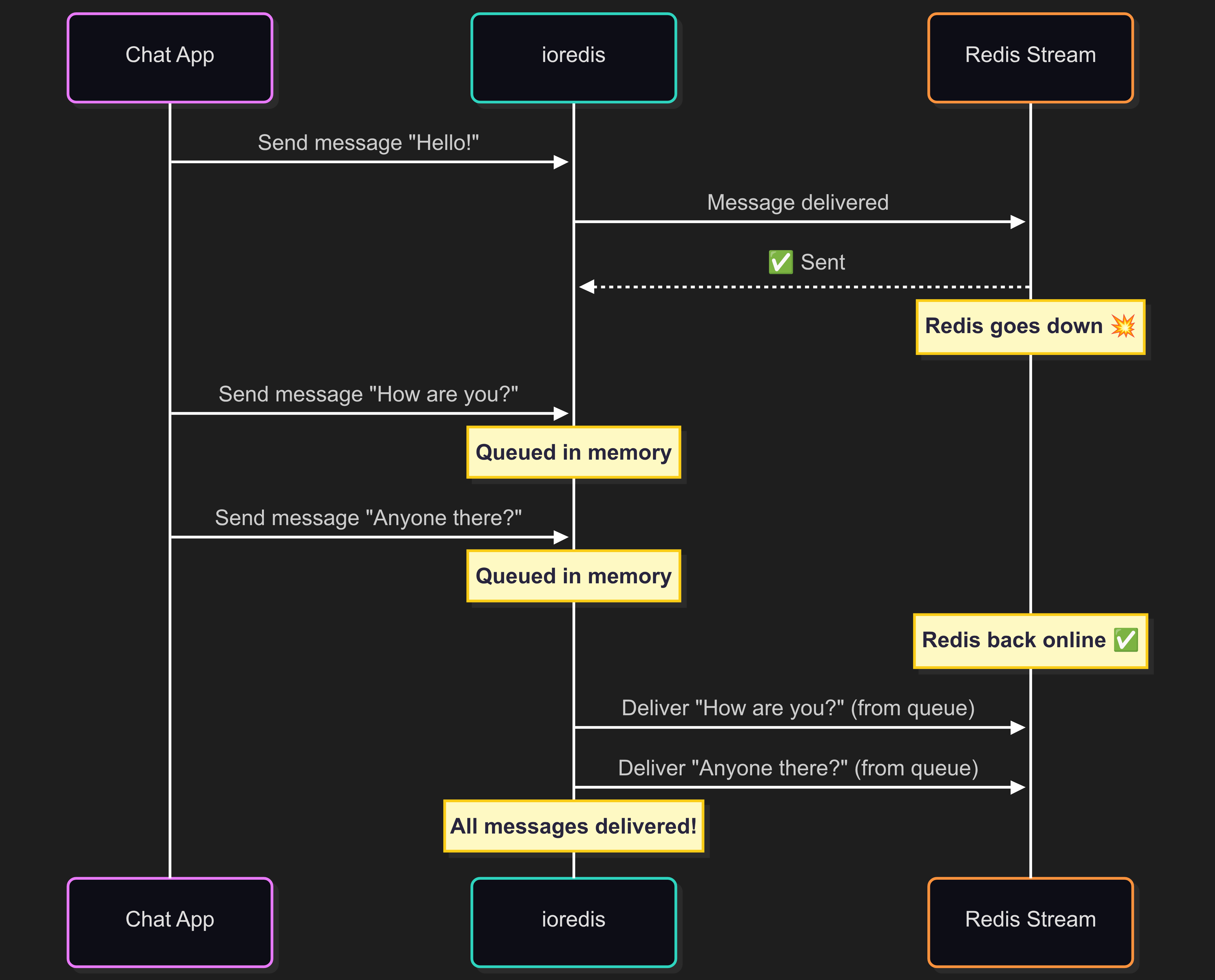
I don’t know if any library in other languages has a similar feature, but I can describe what it looks like in PHP. In PHP, there are probably two main Redis libraries: Predis and PHPRedis (as a C extension). Unfortunately, neither of them provides this functionality. If you need this functionality and cannot ensure an HA configuration, you can try implementing it yourself. It’s probably possible by using APCu storage, which works between all PHP-FPM workers and is a shared storage. However, a better option is to implement a cluster or a sentinel.
Memory size and stream length
Redis stores data in memory, which makes it really fast, that’s well-known. However, this can cause problems, especially with streams. Messages can have different-sized payloads, and sometimes you know the size of the message you can get, but sometimes you have no control over that. For example, consider processing data received from an external system via webhooks.
What is the problem here? Redis Streams actually allows you to set the size of a stream, but only for its length. There is no option to set the maximum memory consumption of a stream. This small detail can sometimes cause problems. How can this problem be handled? There are a few possible solutions.
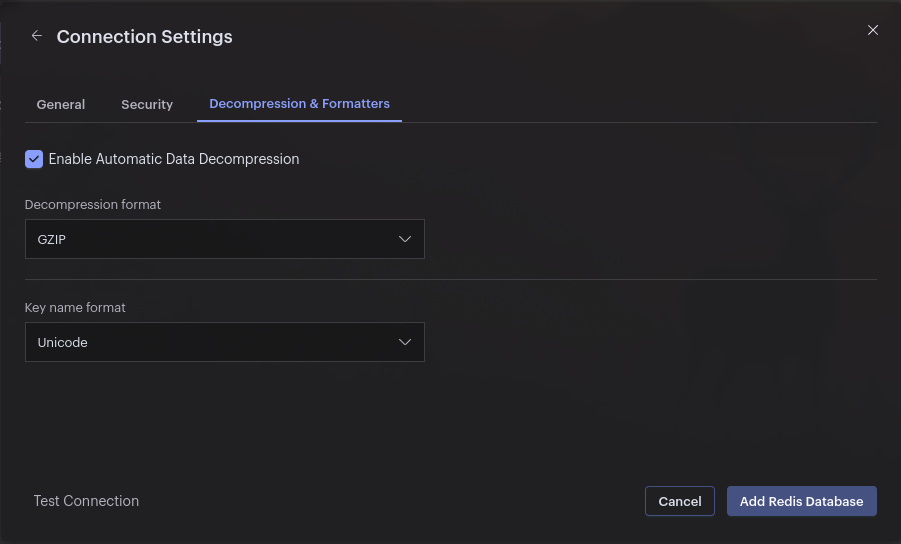
Compress the payload - This solution is simple and effective. Compression is widely adopted by many programming languages, and you can choose from many different compression algorithms. The easiest way to implement this is to use gzip, which is probably available everywhere. You can take the metadata and send it in one non-compressed field. You can add data, such as an identifier or information that helps you decide whether the message should be processed and whether it’s worth uncompressing. In our case, compressing a JSON payload gives us a compression ratio of around 3. It’s also good to mention that you can send compressed binary data directly into the Redis Stream entry field. If you use Redis Insight, you can set the compression method in the connection settings and see the uncompressed data in the stream preview.
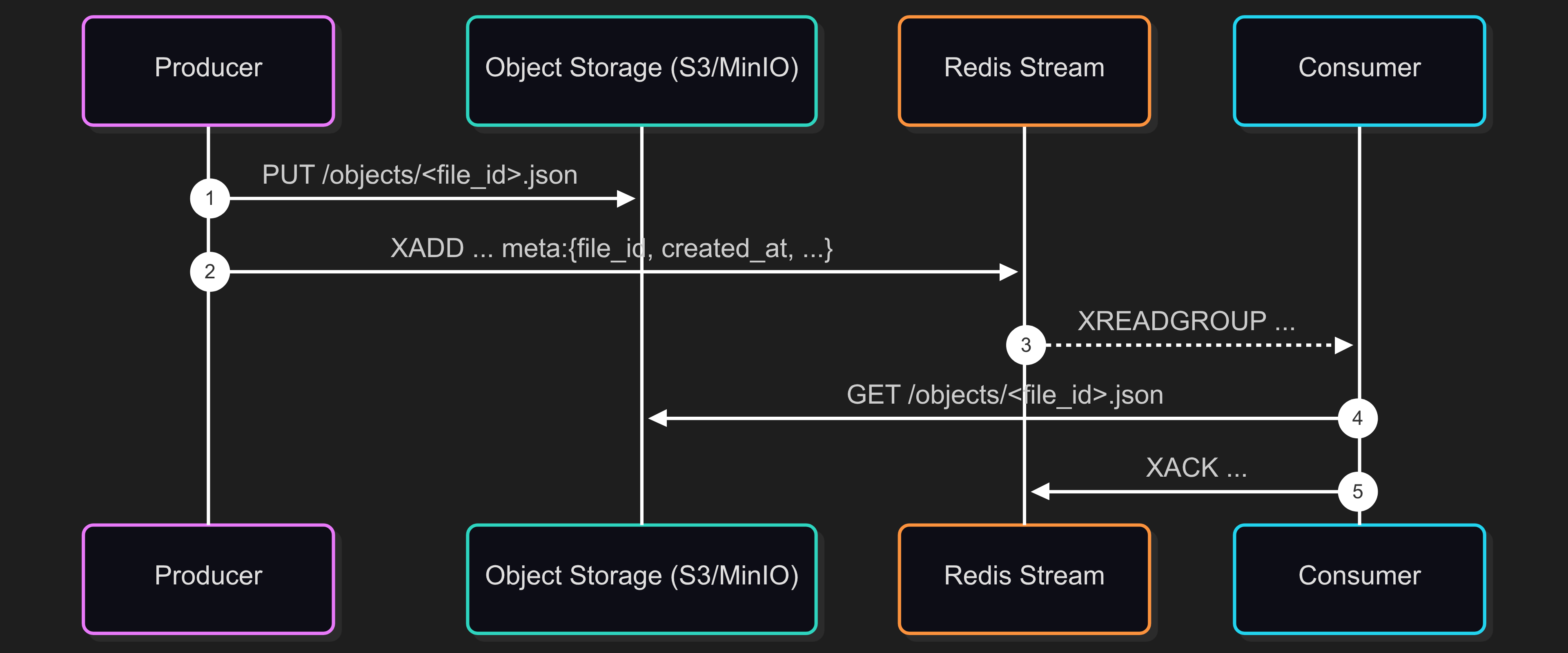
Hybrid Solution - If you know you’ll have to process huge message payloads, you should consider a hybrid solution. For example, you could send only the metadata of a message using a stream and store the rest in S3. This solution is complex, but it will save you if you encounter such a situation. Metadata is more predictable, that can be passed through a stream. By setting the proper stream length, you can easily control memory usage.
Use XACKDEL or XDEL - if you don’t need to store messages for re-reading after processing; you can just delete them. You can use XDEL, but be careful — XDEL removes an entry regardless of whether it was acknowledged by all consumer groups. Since Redis 8.2, you can use XACKDEL, which is useful if you have multiple consumer groups and want to maintain delivery to all groups. You can choose a strategy for removing the entry. For example, you can use ACKED, which removes the entry after processing only if all consumers have acknowledged the message. This option was added to Redis 8.2, which was released a week ago, so it was not available when I started using Redis Streams.
Data eviction policy and streams
This point relates to the previous one. Redis has several strategies for when it runs out of memory. You can remove the latest keys, random keys, etc. Intuitively, you might think that setting maxmemory to remove the oldest keys would remove the oldest messages and everything would be fine. However, that’s not the case: https://github.com/redis/redis/issues/4543. The problem is that “key” is a keyword. In Redis streams, a stream references a key in terms of Redis. So, if you set this policy to LRU, LFU, or Random, and stream is like any other key, it can be removed entirely.
Replaying long streams and persistence
Redis Streams allows you to replay entire stream from the very beginning. Of course only as far as long is your stream, and if you’re not using XDEL after ACK or XACKDEL. But if you really need this possibility to exist, you also need to remember that all this data is stored in the memory, so it’s not persisted. Even if you don’t need to keep very long streams, you should care about the persistence in terms of any outage.
Redis Streams are working same way as all other keys in Redis, and they are also included into persistence settings. So if you already have Redis in your infrastructure or you’re creating a new one, you should take care about this configuration. If you’re not familiar with redis persistence, here you can find all the possible options
Conclusion
Redis Streams is a great alternative to a messaging service like Kafka, especially if you’re looking for simplicity and ease of use. After using Redis Streams in production for a year, I can confidently say that it was the right choice for our use case.
Choose Redis Streams if you:
- Already have Redis in your stack
- Need low latency and moderate throughput
- Want minimal operational complexity
Stick with Kafka if you:
- Need to process millions of messages per second (for sure)
- Need long-term persistence and replay capabilities
- Have a dedicated infrastructure team with knowledge about Kafka
The YAGNI principle applies perfectly here. If you’ve started working with a communication system that uses messaging, you probably don’t need all the fancy features that other solutions has. For many real-world scenarios, Redis Streams might be the sweet spot between functionality and complexity. Redis Streams are also inexpensive to implement, so if you decide to switch to Kafka in the future, you won’t have wasted too much work.
References
- Understanding Streams in Redis and Kafka – A Visual Guide - if you’re considering to use streams IMO it’s obligatory doc to read, even if you’re not choosing between Kafka and Redis, the mechanisms of streams are very well visually explained.
- Kafka, RabbitMQ, and Redis Streams Benchmark - this article may help you to choose better solution from performance perspective
- Redis Streams 8.2 Release changelog - since 8.2, you can use
XACKDELcommand to safely remove processed messages, and still delivery them to all consumer groups. - Note about offline queue in ioredis - useful when you have single non HA Redis instance and want to ensure deliverability
- Redis persistence configuration - you should take care about that if you want your stream to be resistant to any Redis restart